Building AI Readiness: A Data-First Perspective
Introduction
Artificial Intelligence is no longer a future ambition. From predictive models to generative AI and intelligent assistants, organizations are actively experimenting with AI to improve decision-making, efficiency, and user experience. Yet, despite the rapid adoption of advanced algorithms and platforms, many AI initiatives struggle to move beyond pilots or fail to deliver sustained value.
The root cause is rarely the model itself. More often, it lies in the foundations beneath it.
AI systems are only as reliable, fair, and effective as the data they are built on. Without data that is well understood, trusted, protected, and fit for purpose, even the most sophisticated AI solutions will produce fragile or misleading outcomes. As organizations scale their AI ambitions, the question shifts from “Which AI technology should we use?” to “Are we truly ready for AI?”
This article explores AI readiness through the lens of data. Using the Data Tribes framework as a reference, we focus on the data capabilities that enable trustworthy, scalable, and responsible AI, setting aside governance and people-related aspects for deeper discussion in future papers.
The Data Tribes AI Readiness Framework
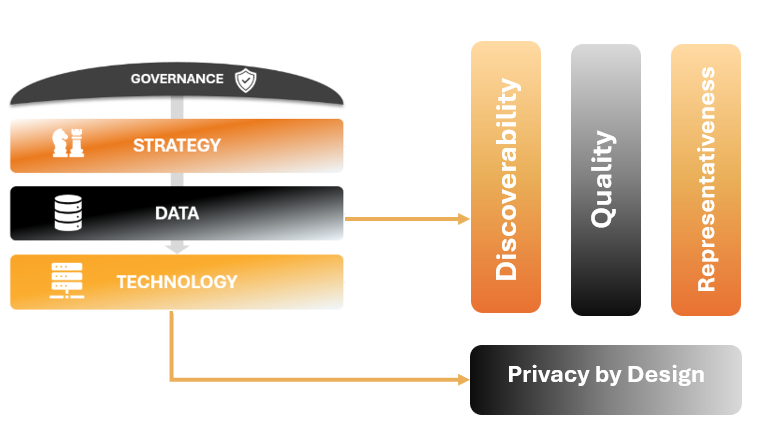
AI readiness is not achieved by deploying a single technology or launching isolated use cases. It is built through a set of foundational capabilities that work together to support sustainable, trustworthy, and scalable AI adoption. At Data Tribes, we frame this journey across four interconnected verticals: Strategy, Data, Technology, and Governance, with People & Culture cutting across all of them.
Within this framework, Data sits at the core. Strategy defines why AI is pursued and what value it should deliver. Technology provides the means to operationalize AI at scale. Governance establishes the rules, accountability, and safeguards that ensure responsible use. But it is data that ultimately determines whether AI initiatives succeed or fail.
This article deliberately focuses on the Data vertical. While governance and people-related aspects are essential to AI maturity, they deserve dedicated treatment. Here, the emphasis is on the data foundations that enable AI systems to be reliable, explainable, and trusted, regardless of the algorithms or platforms in use.
By examining data readiness through this lens, we move away from viewing data as a passive asset and instead treat it as an active enabler of AI outcomes. The sections that follow explore the key characteristics that data must exhibit to truly support AI, from discoverability and privacy to quality, representativeness, and scale.
Discoverability: Making Data Findable and Understandable
One of the most overlooked barriers to AI readiness is not data availability, but data discoverability. Many organizations already possess large volumes of data, yet struggle to identify what data exists, what it represents, and whether it can be safely and effectively used for AI initiatives. From an AI perspective, data that cannot be found or understood might as well not exist.
Discoverability goes far beyond simple data access. It is about enabling both humans and machines to understand data in context. This starts with metadata: the descriptive information that explains what data is, where it comes from, how it is structured, and how it should be interpreted. Technical metadata captures schema, formats, and lineage, while business metadata provides meaning by linking data elements to business concepts and definitions.
A critical enabler of discoverability is a business glossary. By establishing shared definitions for key business terms and mapping them to underlying data assets, organizations create a common language that bridges technical teams, business users, and analytical systems. This shared understanding is essential for AI, where ambiguity in definitions can easily propagate into incorrect predictions or misleading insights.
Beyond traditional metadata, discoverability increasingly relies on a semantic layer. Semantic models enrich data with meaning that machines can reason over, enabling analytics engines, machine learning pipelines, and generative AI applications to interpret data consistently. In the context of GenAI and retrieval-augmented generation (RAG), semantic enrichment becomes even more critical, as models depend on well-described content to retrieve relevant context and produce accurate responses.
Ultimately, discoverable data accelerates AI initiatives by reducing friction. Data scientists spend less time searching and interpreting datasets, AI systems receive clearer signals, and organizations gain confidence that insights and predictions are grounded in well-understood information. Without discoverability, AI remains fragile and dependent on tribal knowledge and manual intervention rather than scalable, repeatable foundations.
Privacy by Design: Protecting Data Without Blocking AI
As AI initiatives increasingly rely on sensitive and personal data, privacy can no longer be treated as an afterthought or a purely technical concern. From an AI readiness perspective, privacy must be designed into the data layer itself, long before models are trained or applications are deployed. This is especially critical when dealing with personally identifiable information (PII), confidential records, or regulated data domains.
At the data level, privacy starts with classification. Organizations must be able to identify and label data based on sensitivity, criticality, and regulatory exposure. This includes distinguishing PII from non-PII data, understanding where sensitive attributes reside, and defining clear usage boundaries. Without proper classification, it becomes impossible to control how data is used in analytics, machine learning, or generative AI scenarios.
However, data classification alone is not sufficient. Privacy must be enforced through the technology layer. This is where protection mechanisms such as access control, encryption, and data masking come into play. Access control ensures that only authorized users, systems, or AI pipelines can interact with sensitive data. Encryption protects data both at rest and in transit, reducing exposure to unauthorized access. Masking and tokenization allow data to remain usable for analytics and AI while minimizing the risk of exposing sensitive values.
The key to AI readiness is the alignment between these two layers. Data teams define what needs protection and why, while technology enforces how that protection is applied consistently and at scale. When this alignment is missing, organizations often face a false trade-off between innovation and compliance, slowing down AI initiatives or introducing unmanaged risk.
Privacy by design removes this tension. By embedding privacy considerations directly into data assets and pipelines, organizations enable AI systems to operate responsibly, compliantly, and with confidence. In doing so, privacy becomes an enabler of trustworthy AI rather than a constraint that limits its adoption.
Data Quality: From Clean Data to Trustworthy AI
Data quality is often discussed as a prerequisite for analytics, but in the context of AI, its role is far more critical. AI systems do not merely consume data — they learn from it, amplify it, and operationalize its patterns at scale. Any weakness in data quality is therefore not just reflected in outputs, but magnified across decisions, predictions, and automated actions.
A fundamental dimension of data quality for AI is timeliness. Models trained on stale or delayed data quickly lose relevance, particularly in dynamic environments where behaviour, demand, or conditions change rapidly. Ensuring data freshness requires reliable pipelines, appropriate latency expectations, and clear alignment between the speed of data delivery and the use case it supports. In AI-driven scenarios, outdated data can be as harmful as incorrect data.
Equally important is understanding the data before using it, which is where Exploratory Data Analysis (EDA) plays a critical role. EDA allows teams to assess distributions, identify missing values, detect anomalies, and uncover hidden biases or inconsistencies. For AI readiness, EDA should not be treated as an ad-hoc activity performed by individual data scientists, but as a structured and repeatable practice embedded into the data lifecycle.
As AI systems scale, visibility into how data flows, becomes essential. Data lineage provides this transparency by tracing data from its source through transformations and pipelines to its final consumption by models and applications. Lineage supports explainability, impact analysis, and confidence in AI outcomes, especially when data sources change or issues arise. Without lineage, diagnosing model behaviour becomes a guessing exercise.
Finally, data quality must be operationalized, not documented. This is achieved through data quality rules implemented directly within data pipelines. Validation checks, monitoring thresholds, and automated alerts ensure that quality expectations are continuously enforced rather than assumed. When quality degrades, issues are detected early, before flawed data reaches AI models and affects outcomes.
Together, timeliness, EDA, lineage, and embedded quality rules transform data quality from a reactive cleanup effort into a proactive capability. This shift is essential for building AI systems that are not only performant, but reliable, explainable, and trusted over time.
Representativeness: Volume and Variety Without Bias
AI models are often described as being “data-hungry,” but volume alone does not guarantee reliable or fair outcomes. From an AI readiness perspective, the real objective is representativeness, ensuring that the data used to train and operate AI systems adequately reflects the reality they are expected to model.
Volume plays an important role in AI. Sufficient data is required to capture meaningful patterns, reduce noise, and improve statistical confidence. When datasets are too small, models may overfit, behave unpredictably, or fail to generalize beyond narrow scenarios. However, accumulating large volumes of data without purpose can introduce complexity without improving outcomes.
Equally critical is variety. AI systems trained on narrow or homogeneous datasets are more likely to reproduce existing biases, overlook edge cases, or perform poorly when exposed to new conditions. Variety ensures that data covers different populations, behaviours, scenarios, and operating conditions relevant to the problem space. This is particularly important in AI systems that influence decisions affecting people, services, or access to resources.
Representativeness sits at the intersection of volume and variety. It requires deliberate choices about which data sources are included, which scenarios are captured, and which gaps remain. Without this intentionality, AI systems may appear accurate during testing but fail when deployed in real-world environments that differ from their training data.
By treating representativeness as a core data capability rather than a statistical afterthought, organizations reduce the risk of biased outcomes and improve the robustness of their AI systems. This approach shifts the focus from simply “having more data” to having the right data, aligned with the context and impact of the AI use case.
Data as an Enabler & Not a Bottleneck for AI
When data is discoverable, protected by design, continuously trusted, and representative of real-world conditions, it stops being a constraint on AI initiatives and becomes their primary accelerator. Teams spend less time compensating for data issues and more time focusing on experimentation, validation, and impact. AI systems become easier to scale, explain, and maintain because the foundations beneath them are stable and well understood.
In contrast, weak data foundations force organizations into reactive patterns, fixing issues after models fail, questioning outputs without clear answers, or limiting AI adoption due to unmanaged risk. Data readiness, therefore, is not a technical prerequisite but a strategic enabler that directly influences the speed, reliability, and credibility of AI outcomes.
Closing Thoughts: Building the Foundations for Trustworthy AI
AI readiness is not achieved through models alone. It is built through disciplined data practices that prioritize understanding, trust, and responsibility. Discoverability, privacy, quality, and representativeness are not isolated concerns. Together, they define whether AI systems can be relied upon to support real decisions in real environments.
This belief sits at the core of Data Tribes. The platform and community were created to help organizations and individuals move beyond fragmented initiatives and build strong data foundations that can sustain AI over time. Through shared knowledge, practical guidance, and a common language around data and AI, Data Tribes aims to support the journey from experimentation to maturity.
As AI continues to evolve, the need for strong data foundations will only grow. In upcoming articles and papers, we will explore the complementary dimensions of this journey, including data governance, people and culture, and organizational enablement, completing the picture of what it truly means to be AI-ready.